开始
消耗和速率限制
每grokmodel 具有不同的速率限制。要检查团队的速率限制,您可以访问 xAI 控制台型号页面。
要请求更高的速率限制,请向 support@x.ai 发送电子邮件,并提供您的预期流量。
如果您是团队管理员,Usage Explorer 是一个有用的工具,可用于监控团队在 API 上的总支出和使用情况。
计算消耗量的基本单位 — 代币
Token 是用于模型推理和定价目的的 prompt 大小的基本单位。它由一个或多个字符/符号组成。
当 Grok 模型处理您的请求时,输入提示将通过分词器分解为令牌列表。 然后,该模型将根据提示标记进行推理,并生成完成标记。 推理完成后,完成令牌将聚合到发回给您的完成响应中。
您可以在 xAI 控制台上使用 Tokenizer 来可视化令牌并计算给定文本提示的令牌总数。
文本标记
标记可以是整个单词,也可以是较小的字符组合块。单词越常见,它就越有可能是整个标记。
例如,Flint 被分解为两个代币,而 Michigan 是一个完整的代币。

在另一个例子中,大多数单词本身就是标记,但“drafter”被分解为“dra”和“fter”,而“postmaster”被分解为“post”和“master”。

对于给定的文本/图像/等提示符或完成序列,不同的分词器可能会将其分解为不同长度的列表。
不同的 Grok 模型也可能共享或使用不同的分词器。因此,相同的提示/完成序列在不同模型中可能没有相同数量的令牌。
提示/完成序列中的令牌计数应与序列长度大致线性。
图像提示令牌
每个图像提示将需要 256 到 1792 个令牌,具体取决于图像的大小。图像 + 文本标记计数必须小于模型的整体上下文窗口。
在 xAI 控制台上使用 tokenizer 或通过 API 估算消耗量
在 xAI 控制台上,您可以使用 tokenizer 页面来估计您的文本提示将消耗多少个令牌。例如,要发送的以下消息grok-2-vision-1212将消耗 5 个代币。
消息正文:
json
[
{
role: "user",
content:
"How is the weather today?"
}
]
在 Tokenizer 页面上对结果进行 Tokenize 处理:
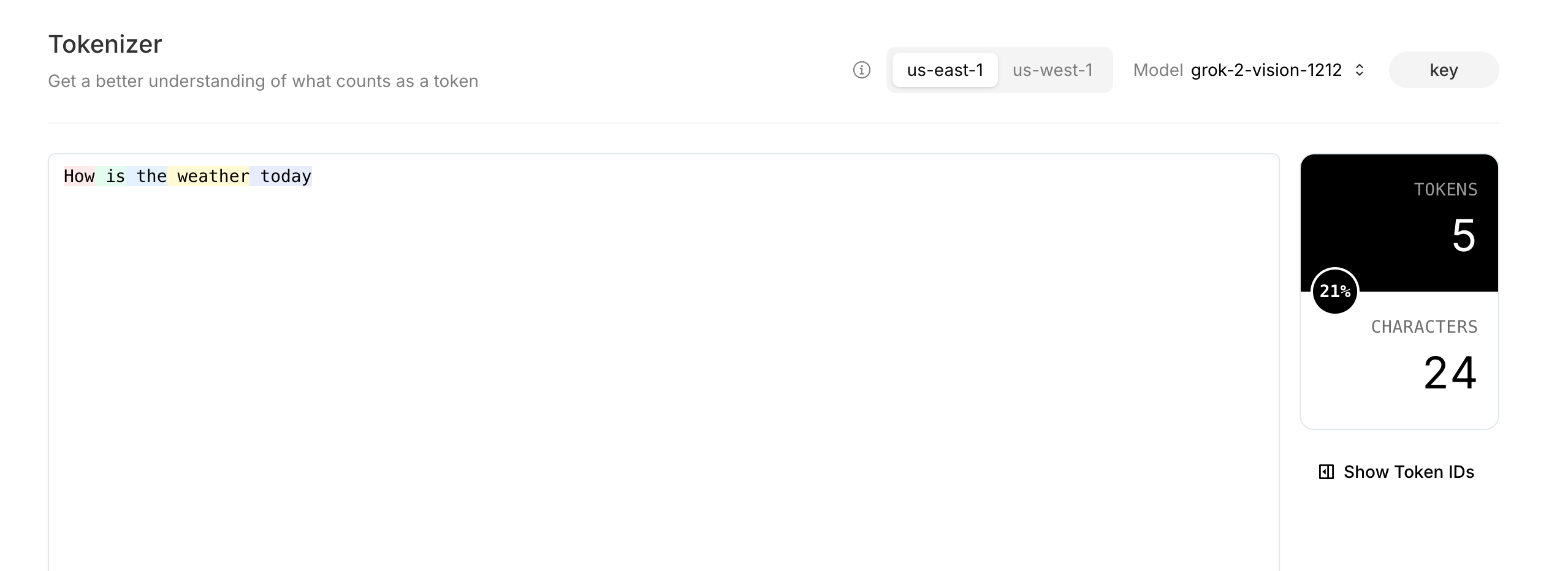
您还可以利用 Tokenize Text API 端点对文本进行 Tokenize ,并计算输出令牌数组长度。
达到速率限制
对于每个层级,每分钟都有最大请求数。这是为了确保系统的所有用户都能公平使用。
一旦您的请求频率达到速率限制,您将收到错误代码429作为回应。
您可以:
- 将您的团队升级到更高级别
- 更改您的使用模式以减少发送的请求
检查 Token 消耗
在每个完成响应中,都有一个usage对象,详细说明您的提示和完成令牌计数。您可能会发现跟踪它很有帮助,以避免达到速率限制或出现成本意外。
json
"usage": {
"prompt_tokens": 41,
"completion_tokens": 87,
"total_tokens": 128,
"prompt_tokens_details": {
"text_tokens": 41,
"audio_tokens": 0,
"image_tokens": 0,
"cached_tokens": 0
}
}
您还可以使用 OpenAI 或 Anthropic SDK 进行检查。 OpenAI 开发工具包:
import os
from openai import OpenAI
XAI_API_KEY = os.getenv("XAI_API_KEY")
client = OpenAI(base_url="https://api.x.ai/v1", api_key=XAI_API_KEY)
completion = client.chat.completions.create(
model="grok-2-latest",
messages=[
{
"role": "system",
"content": "You are Grok, a chatbot inspired by the Hitchhikers Guide to the Galaxy.",
},
{
"role": "user",
"content": "What is the meaning of life, the universe, and everything?",
},
],
)
if completion.usage:
print(completion.usage.to_json())