Getting Started
Consumption and Rate Limits
Each grok model has different rate limits. To check your team's rate limits, you can visit xAI Console Models Page.
To request a higher rate limit, please email support@x.ai with your anticipated volume.
If you're a team admin, the Usage Explorer is a helpful tool to monitor your team's total spend and usage on the API.
Basic unit to calculate consumption — Tokens
Token is the base unit of prompt size for model inference and pricing purposes. It is consisted of one or more character(s)/symbol(s).
When a Grok model handles your request, an input prompt will be decomposed into a list of tokens through a tokenizer. The model will then make inference based on the prompt tokens, and generate completion tokens. After the inference is completed, the completion tokens will be aggregated into a completion response sent back to you.
You can use Tokenizer on xAI Console to visualize tokens and count total token counts for a given text prompt.
Text tokens
Tokens can be either of a whole word, or smaller chunks of character combinations. The more common a word is, the more likely it would be a whole token.
For example, Flint is broken down into two tokens, while Michigan is a whole token.

In another example, most words are tokens by themselves, but "drafter" is broken down into "dra" and "fter", and "postmaster" is broken down into "post" and "master".

For a given text/image/etc. prompt or completion sequence, different tokenizers may break it down into different lengths of lists.
Different Grok models may also share or use different tokenizers. Therefore, the same prompt/completion sequence may not have the same amount of tokens across different models.
The token count in a prompt/completion sequence should be approximately linear to the sequence length.
Image prompt tokens
Each image prompt will take between 256 to 1792 tokens, depneding on the size of the image. The image + text token count must be less than the overall context window of the model.
Estimating consumption with tokenizer on xAI Console or through API
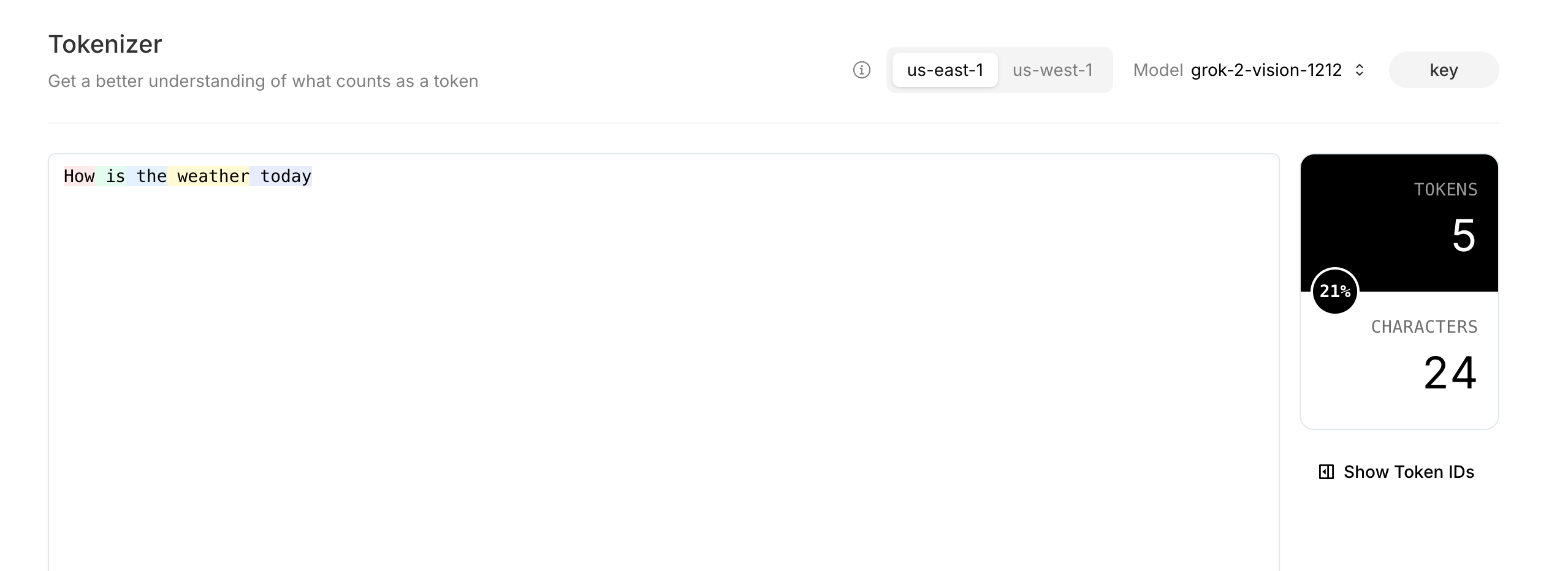
On xAI Console, you can use the tokenizer page to estimate how many tokens your text prompt will consume. For example, the following message to be sent to use grok-2-vision-1212 would consume 5 tokens.
Message body:
json
[
{
role: "user",
content:
"How is the weather today?"
}
]
Tokenize result on Tokenizer page:
You can also utilize the Tokenize Text API endpoint to tokenize the text, and count the output token array length.
Hitting rate limits
For each tier, there is a maximum amount of requests per minute. This is to ensure fair usage by all users of the system.
Once your request frequency has reached the rate limit, you will receive error code 429 in response.
You can either:
- Upgrade your team to higher tiers
- Change your consumption pattern to send less requests
Checking token consumption
In each completion response, there is a usage object detailing your prompt and completion token count. You might find it helpful to keep track of it, in order to avoid hitting rate limits or having cost surprises.
json
"usage": {
"prompt_tokens": 41,
"completion_tokens": 87,
"total_tokens": 128,
"prompt_tokens_details": {
"text_tokens": 41,
"audio_tokens": 0,
"image_tokens": 0,
"cached_tokens": 0
}
}
You can also check with OpenAI or Anthropic SDKs. OpenAI SDK:
import os
from openai import OpenAI
XAI_API_KEY = os.getenv("XAI_API_KEY")
client = OpenAI(base_url="https://api.x.ai/v1", api_key=XAI_API_KEY)
completion = client.chat.completions.create(
model="grok-2-latest",
messages=[
{
"role": "system",
"content": "You are Grok, a chatbot inspired by the Hitchhikers Guide to the Galaxy.",
},
{
"role": "user",
"content": "What is the meaning of life, the universe, and everything?",
},
],
)
if completion.usage:
print(completion.usage.to_json())